Il motore di ricerca è un’applicazione web creata per cercare informazioni sul World Wide Web (www).
I risultati di ricerca vengono mostrati in un indice gerarchico dicontenuti, la SERP (Search Engine Results Page).
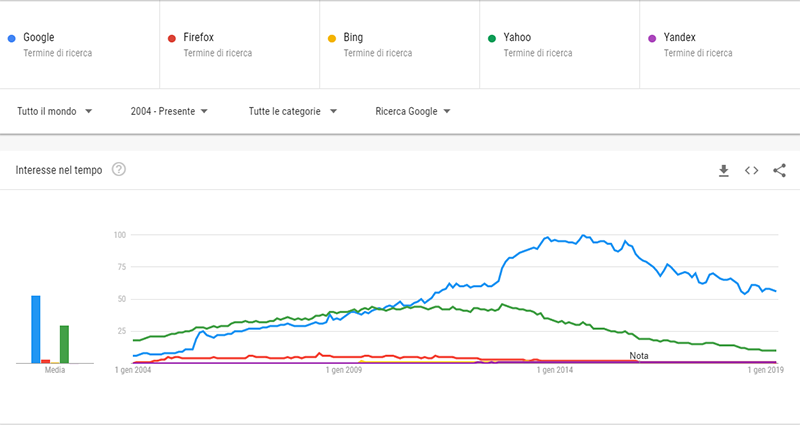
Attualmente il motore di ricerca più utilizzato (manco a dirlo) è Google. Lo seguono Yahoo!, Firefox, Bing e Yandex (utilizzato soprattutto in Russia, dato che possiede degli algoritmi studiati appositamente per le ricerche in alfabeto cirillico).
Cito anche DuckDuckGo che si sta diffondendo rapidamente, soprattutto negli Stati Uniti. Esso si distingue per la volontà di non salvare le informazioni di navigazione degli utenti. Viste le vicende legate alla privacy, GDPR e multe a Big Company come Facebook, è probabile che questo motore continui a crescere 🙂
Come funzionano i motori di ricerca
Cosa accade dietro le quinte del motore di ricerca? 🤔
Il motore di ricerca (per spiegarlo in modo semplice) opera attraverso tre fasi principali:
crawling;
parsing;
rendering.
Crawling
Per creare la classifica di contenuti che ritroviamo in SERP, i motori di ricerca devono in qualche modo “leggere” i siti web: più nel dettaglio, esaminano il codice HTML di tutti i documenti presenti sul web.
Per far questo, si avvalgono dei Crawler (chiamati anche Bot, Spider o Robot) che scansionano le pagine web da cima a fondo e raccolgono le informazioni principali per salvarle nel database del motore.
Prima di iniziare l’analisi del sito, i crawler leggono (se disponibile nel sito) il file robots.txt. È un file che viene dato in pasto ai crawler con le indicazioni di cosa possono scannerizzare nel sito e cosa no.
Nonostante la presenza di questo file, sta al crawler la scelta di rispettare le direttive o fare a meno.
Un po’ come i limiti di velocità in una strada senza autovelox 🙂
In ogni caso, il crawler si sofferma su alcune parti specifiche che compongono il codice: il tag title della pagina, la meta description, gli heading tag, gli alt text delle immagini, le parti in grassetto o in corsivo del testo e i link.
Tra queste componenti, il crawler andrà alla ricerca delle keyword più ricorrenti e rilevanti che saranno utili nel processo di indicizzazione.
Fatto questo, lo spider immagazzina tutti i dati raccolti nel database del motore di ricerca.
Ovviamente non è finita qui: a intervalli regolari il crawler tornerà sui siti già scansionati alla ricerca di variazioni e nuovi contenuti.
Parsing
Nella fase del parsing, la mole di dati salvata nel database del motore viene messa in ordine.
Il motore di ricerca ordina le pagine per contenuto semantico, cercando di collegarle alle query inserite degli utenti.
Rendering
Quando l’utente inserisce la query, il motore — attraverso evoluti algoritmi — preleva dal database i contenuti più vicini semanticamente alla query, ordinandoli in un indice gerarchico.
Il criterio con cui vengono valutati i siti è in parte segreto e varia da motore a motore. Tuttavia, sappiamo che, per decidere questo ranking, la maggior parte dei motori di ricerca prendono in considerazione questi fattori:
le parole più frequentemente ricercate all’interno della pagina;
la presenza delle parole che formano la query nell’URL, nel meta-tag title, nel titolo e nelle prime righe del testo;
i sinonimi delle parole ricercate;
la qualità del sito;
l’autorevolezza del sito, stabilita dal motore di ricerca attraverso l’analisi semantica e l’analisi dei link in entrata.
Dopo la fase di ranking, finalmente viene creata la SERP, la classifica finale dei risultati di ricerca dal contenuto migliore (voto più alto) al peggiore (voto più basso).
Quindi, se il primo risultato nella SERP è anche quello con il voto più alto, gli utenti saranno portati ad esplorare proprio quel contenuto. Ecco perché è così importante la SEO (Search Engine Optimization), ossia l’insieme di tecniche finalizzate a migliorare il posizionamento di una pagina web nella SERP dei motori di ricerca.
Un po’ di storia: le ere dei motori di ricerca
L’era delle Directory
All’inizio degli anni ’90, poco dopo la creazione del codice HTML, si cominciava a sentire l’esigenza di catalogare i contenuti presenti in rete.
Questo ha portato alla creazione delle directory, veri e propri “schedari” dei siti web che si dividevano in categorie e varie sottocategorie.
All’epoca, la facevano da padroni i motori YahooDirectory e il suo rivale DMOZ. Ti ricordi? 🙂
Ma come si inseriva un sito nelle directory?
I webmaster del tempo dovevano inviare agli editor (uno staff di volontari) una richiesta di inserimento del sito all’interno di una specifica categoria della directory.
Molto spesso, però, questi editor erano degli specialisti SEO già operanti presso altre aziende e potevano mettere i bastoni tra le ruote ai competitor, bocciando o rallentando la catalogazione dei siti avversari.
Un altro problema della revisione degli editor era che i siti da esaminare erano numerosissimi e i tempi di posizionamento nelle directory diventavano sempre più lunghi.
L’era dei metamotori
Sempre all’inizio degli anni 90, altri motori di ricerca come Infoseek e AltaVista hanno iniziato ad utilizzare gli spider, i quali avevano il compito di passare da link a link ed esaminare le pagine web. Una volta completata la verifica dello spider, i siti venivano approvati immediatamente.
Tuttavia, a causa della banda molto limitata, gli spider non avevano né il tempo né una connessione abbastanza potente per scannerizzare l’intera pagina web, quindi si limitavano all’head del sito. Per questo motivo, sono stati creati i meta tags (come meta title, meta description, meta keywords).
L’evoluzione di metamotori con la lettura del body
Con l’evoluzione tecnologica, gli spider iniziarono finalmente ad analizzare anche il body.
All’epoca il criterio degli spider per capire l’autorevolezza di un sito era… (tieniti forte) la keyword density!
Ergo, più si ripeteva una keyword all’interno del sito e più si guadagnavano posizioni in SERP.
Come immaginabile, i webmaster non solo infilavano le keyword ovunque possibile, ma addirittura ammucchiavano le parole chiave alla fine di un paragrafo di testo, mimetizzandole col colore di sfondo (che bellissimo #barbatrucco)!
Ovviamente queste schifezze non funzionano più.
La Link Popularity
Insomma, posizionare un sito in SERP sembrava un’impresa fuori dalla portata perfino dello spider.
Su cosa si poteva fare affidamento per capire se un sito fosse realmente autorevole?
A questo punto, i fondatori di Yahoo! si affidarono alla link popularity e ai backlink, ossia i link in entrata. Il concetto è semplice: più siti linkano ad una pagina web e più quella pagina web sarà autorevole.
Ma anche questa strategia sembra fare acqua: i siti, infatti, iniziarono a scambiarsi link a vicenda solo per guadagnare posizioni.
Gli albori dell’era di Google
E qui inizia il bello! 🙂
Dato che utilizzare la link popularity come criterio per la valutazione dei siti era comunque una buona idea, Larry Page decise di migliorarla, focalizzandosi sia sui link in entrata sia sui link in uscita.
Da qui in poi, Google si è impegnata costantemente a rilasciare degli algoritmi sempre più intelligenti per migliorare l’analisi dei siti web.
Ecco una rapida carrellata.
Panda
Ricordi che a Google piacciono gli animali, no? Ecco, partiamo con Google Panda 😀
Panda è un algoritmo che mira a ridurre il posizionamento di siti di bassa qualità e che penalizza i contenuti duplicati.
Pinguino
Nel 2012 è stato lanciato Google Pinguino. Il suo scopo è individuare i link tossici e bloccare tutti quei siti che fanno uso di tecniche Black Hat SEO (ossia quelle tecniche che non rispettano le regole previste da Google).
Hummingbird
Sempre nel 2012 compare Hummingbird, un potente algoritmo di machine learning in grado di “leggere“ approfonditamente il contenuto del sito.
Questo algoritmo è in grado di interpretare lo user intent grazie alla semantica delle parole: non solo comprende i sinonimi, ma riesce a desumere il contesto dalla query.
Mobilegeddon, Pidgeon e Possum
Nel 2015, invece, viene rilasciato Mobilegeddon assieme a Pidgeon e Possum.
Mobilegeddonpremia i siti mobile friendly.
Pidgeon, invece, favorisce i siti che curano il local business e chi possiede la cartolina Google My Business.
Possum ottimizza i risultati di ricerca a seconda della geolocalizzazione.
RankBrain
Rankbrain è un sistema di intelligenza artificiale che interviene nella scelta del ranking dei risultati di ricerca.
Come Hummingbird, anche RankBrain è in grado di determinare l’intento di ricerca degli utenti e non solo: se RankBrain legge una keyword che non conosce, può indovinare quali parole o frasi possano avere un significato simile e filtrare il risultato di conseguenza, rendendo più efficace la gestione delle query di ricerca.
Fred
Nel marzo del 2017 ha fatto la sua comparsa Fred.
Quest’ultimo update penalizza i siti web con adstroppo aggressive e invasive. Premia, invece, la freschezza dei contenuti.
Insomma, dietro al motore di ricerca c’è un affascinante mondo fatto di algoritmi, crawler e intelligenza artificiale.